
PygmalionAI's large-scale inference engine
pygmalion.chat
It is designed to serve as the inference endpoint for the PygmalionAI website, and to allow serving the Pygmalion models to a large number of users with blazing fast speeds (thanks to vLLM's Paged Attention).
 AlpinDale
ed6717d0c0
feat: initial support for control vectors
AlpinDale
ed6717d0c0
feat: initial support for control vectors
|
4 tháng trước cách đây | |
|---|---|---|
| .github | 4 tháng trước cách đây | |
| aphrodite | 4 tháng trước cách đây | |
| assets | 10 tháng trước cách đây | |
| cmake | 5 tháng trước cách đây | |
| docker | 4 tháng trước cách đây | |
| docs | 4 tháng trước cách đây | |
| examples | 4 tháng trước cách đây | |
| kernels | 4 tháng trước cách đây | |
| tests | 4 tháng trước cách đây | |
| .clang-format | 5 tháng trước cách đây | |
| .dockerignore | 5 tháng trước cách đây | |
| .env | 5 tháng trước cách đây | |
| .gitignore | 4 tháng trước cách đây | |
| CMakeLists.txt | 4 tháng trước cách đây | |
| CODE_OF_CONDUCT.md | 6 tháng trước cách đây | |
| CONTRIBUTING.md | 6 tháng trước cách đây | |
| Dockerfile | 4 tháng trước cách đây | |
| Dockerfile.cpu | 4 tháng trước cách đây | |
| Dockerfile.neuron | 5 tháng trước cách đây | |
| Dockerfile.openvino | 4 tháng trước cách đây | |
| Dockerfile.ppc64le | 5 tháng trước cách đây | |
| Dockerfile.rocm | 4 tháng trước cách đây | |
| Dockerfile.tpu | 4 tháng trước cách đây | |
| Dockerfile.xpu | 5 tháng trước cách đây | |
| LICENSE | 1 năm trước cách đây | |
| MANIFEST.in | 5 tháng trước cách đây | |
| README.md | 8 tháng trước cách đây | |
| build-linux-wheel.sh | 8 tháng trước cách đây | |
| docker-compose.yml | 5 tháng trước cách đây | |
| entrypoint.sh | 5 tháng trước cách đây | |
| env.py | 9 tháng trước cách đây | |
| environment.yaml | 4 tháng trước cách đây | |
| formatting.sh | 5 tháng trước cách đây | |
| mypy.ini | 8 tháng trước cách đây | |
| patch_xformers.rocm.sh | 10 tháng trước cách đây | |
| pyproject.toml | 4 tháng trước cách đây | |
| requirements-build.txt | 4 tháng trước cách đây | |
| requirements-common.txt | 4 tháng trước cách đây | |
| requirements-cpu.txt | 5 tháng trước cách đây | |
| requirements-cuda.txt | 4 tháng trước cách đây | |
| requirements-dev.txt | 5 tháng trước cách đây | |
| requirements-neuron.txt | 8 tháng trước cách đây | |
| requirements-openvino.txt | 4 tháng trước cách đây | |
| requirements-rocm.txt | 4 tháng trước cách đây | |
| requirements-tpu.txt | 5 tháng trước cách đây | |
| requirements-xpu.txt | 5 tháng trước cách đây | |
| runtime.sh | 10 tháng trước cách đây | |
| setup.py | 4 tháng trước cách đây | |
| update-runtime.sh | 8 tháng trước cách đây |
README.md
Breathing Life into Language

Aphrodite is the official backend engine for PygmalionAI. It is designed to serve as the inference endpoint for the PygmalionAI website, and to allow serving the Pygmalion models to a large number of users with blazing fast speeds (thanks to vLLM's Paged Attention).
Aphrodite builds upon and integrates the exceptional work from various projects.
The compute necessary for Aphrodite's development is provided by Arc Compute.
Features
- Continuous Batching
- Efficient K/V management with PagedAttention from vLLM
- Optimized CUDA kernels for improved inference
- Quantization support via AQLM, AWQ, Bitsandbytes, EXL2, GGUF, GPTQ, QuIP#, Smoothquant+, and SqueezeLLM
- Distributed inference
- Variety of sampling methods (Mirostat, Locally Typical Sampling, Tail-Free Sampling, etc)
- 8-bit KV Cache for higher context lengths and throughput, at both FP8 and INT8 formats.
Quickstart
Install the engine:
$ pip install -U aphrodite-engine --extra-index-url https://downloads.pygmalion.chat/whl
Then launch a model:
$ aphrodite run meta-llama/Meta-Llama-3-8B-Instruct
This will create a OpenAI-compatible API server that can be accessed at port 2242 of the localhost. You can plug in the API into a UI that supports OpenAI, such as SillyTavern.
Please refer to the wiki for the full list of arguments and flags you can pass to the engine.
You can play around with the engine in the demo here:
![]()
Docker
Additionally, we provide a Docker image for easy deployment. Here's a basic command to get you started:
sudo docker run -d -e MODEL_NAME="mistralai/Mistral-7B-Instruct-v0.2" -p 2242:2242 --gpus all --ipc host alpindale/aphrodite-engine
This will pull the Aphrodite Engine image (~9GiB download), and launch the engine with the Mistral-7B model at port 2242. Check here for the full list of env variables.
See here for the Compose file to use with Docker Compose.
Requirements
- Operating System: Linux (or WSL for Windows)
- Python: at least 3.8
For windows users, it's recommended to use tabbyAPI instead, if you do not need batching support.
Build Requirements:
- CUDA >= 11
For supported GPUs, see here. Generally speaking, all semi-modern GPUs are supported - down to Pascal (GTX 10xx, P40, etc.)
Installation
Usage
For usage, please refer to the wiki page for detailed instructions. Aphrodite provides many different options for LLM inference, so please read through the list of options here.
Performance
Speeds vary with different GPUs, model sizes, quantization schemes, batch sizes, etc. Here are some baseline benchmarks conducted by requesting as many completions as possible from the API server.
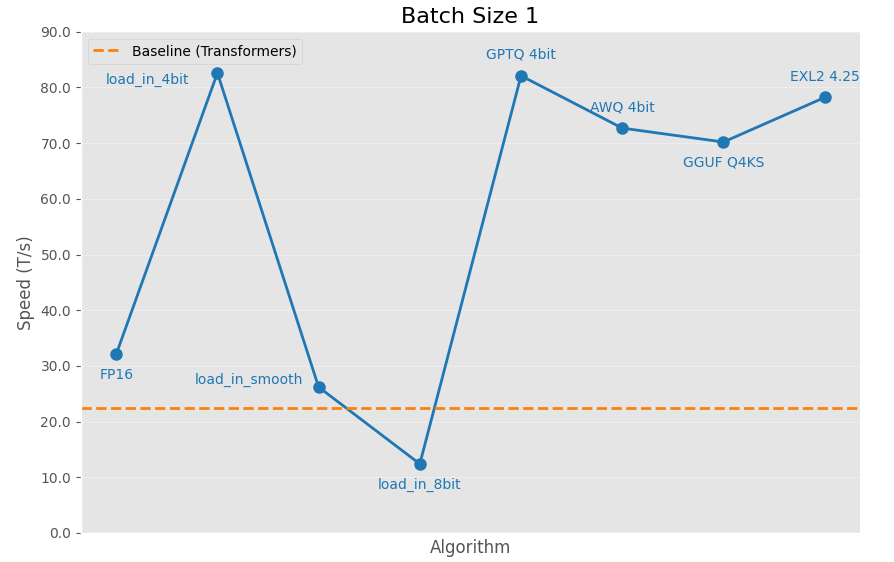
Batch Size 1 Performance
These are the speeds a user would normally get if they request a single output with a sizable prompt and output length. Essentially, normal chatting experience.
The following results were gathered by sending a request with 8192 prompt tokens and requesting 1024 tokens with ignore_eos=True.
GPU: NVIDIA A40, Mistral 7B. Baseline is the same model loaded with text-generation-webui in FP16.
High Batch Size Performance
Work in Progress.
Notes
By design, Aphrodite takes up 90% of your GPU's VRAM. If you're not serving an LLM at scale, you may want to limit the amount of memory it takes up. You can do this in the API example by launching the server with the
--gpu-memory-utilization 0.6(0.6 means 60%).You can view the full list of commands by running
aphrodite run --help.Context Length extension via the RoPE method is supported for most models. Use the command-line flag
--max-model-lento specify a desired context length and the engine will adjust the RoPE scaling accordingly.Please refer to the FAQ & Issues if you run into problems. If you don't find an answer there, please make an issue.
Acknowledgements
Aphrodite Engine would have not been possible without the phenomenal work of other open-source projects. Credits go to:
- vLLM (CacheFlow)
- TensorRT-LLM
- xFormers
- AutoAWQ
- AutoGPTQ
- SqueezeLLM
- Exllamav2
- TabbyAPI
- AQLM
- KoboldAI
- Text Generation WebUI
- Megatron-LM
- Ray
Contributing
Everyone is welcome to contribute. You can support the project by opening Pull Requests for new features, fixes, or general UX improvements.