|
|
@@ -48,6 +48,15 @@ create an OpenAI-compatible API.
|
|
|
## Performance
|
|
|
Speeds vary with different GPUs, model sizes, quantization schemes, batch sizes, etc. Here are some baseline benchmarks conducted by requesting as many completions as possible from the [API server](https://github.com/PygmalionAI/aphrodite-engine/blob/main/aphrodite/endpoints/openai/api_server.py). Keep in mind that these are the theoritical peak throughput with parallel decoding, with as high a batch size as possible. **Per-request generation speed is a fraction of this, at 30-40 t/s**.
|
|
|
|
|
|
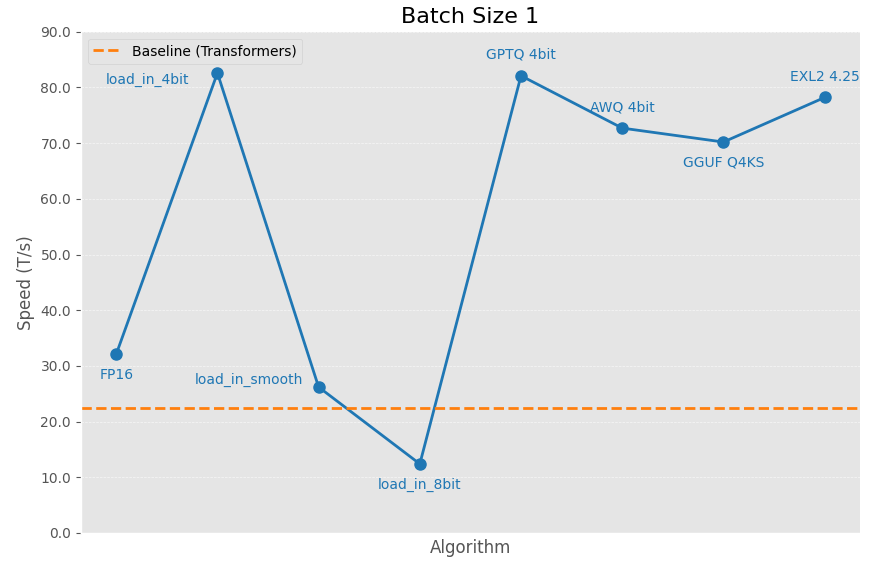
+### Batch Size 1 Performance
|
|
|
+These are the speeds a user would normally get if they request a single output with a sizable prompt and output length. Essentially, normal chatting experience.
|
|
|
+
|
|
|
+The following results were gathered by sending a request with 8192 prompt tokens and requesting 1024 tokens with `ignore_eos=True`.
|
|
|
+
|
|
|
+GPU: NVIDIA A40
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
### High Batch Size Performance
|
|
|
|
|
|
> [!NOTE]
|
|
|
@@ -74,29 +83,6 @@ Throughput refers to output tokens per second.
|
|
|
| | | Q8 | RTX 4090 | 2647.0 |
|
|
|
| | SqueezeLLM | 4 | RTX 4090 | 580.3 |
|
|
|
|
|
|
-### Batch Size 1
|
|
|
-These are the speeds a user would normally get if they request a single output with a sizable prompt and output length. Essentially, normal chatting experience.
|
|
|
-
|
|
|
-The following results were gathered by sending a request with 2000 prompt tokens and requesting 1024 tokens with `ignore_eos=True`.
|
|
|
-
|
|
|
-| Model | Quantization | bits | GPU | Throughput (T/s) |
|
|
|
-| ---------- | ------------ | ---- | -------- | ---------------- |
|
|
|
-| Mistral 7B | None | 16 | RTX 4090 | 54.0 |
|
|
|
-| | AWQ | 4 | RTX 4090 | 128.2 |
|
|
|
-| | GPTQ | 8 | RTX 4090 | 92.8 |
|
|
|
-| | | 4 | RTX 4090 | **146.8** |
|
|
|
-| | GGUF | Q8 | RTX 4090 | 91.0 |
|
|
|
-| | | Q6KM | RTX 4090 | 105.4 |
|
|
|
-| | | Q5KM | RTX 4090 | 117.8 |
|
|
|
-| | | Q4KM | RTX 4090 | 128.9 |
|
|
|
-| Llama-2 7B | None | 16 | RTX 4090 | 55.2 |
|
|
|
-| | GPTQ | 8 | RTX 4090 | 90.2 |
|
|
|
-| | | 4 | RTX 4090 | **128.0** |
|
|
|
-| | AWQ | 4 | RTX 4090 | 116.3 |
|
|
|
-| | GGUF | Q8 | RTX 4090 | 88.1 |
|
|
|
-| | | Q6KM | RTX 4090 | 99.4 |
|
|
|
-| | | Q5KM | RTX 4090 | 109.9 |
|
|
|
-| | | Q4KM | RTX 4090 | 118.9 |
|
|
|
|
|
|
## Requirements
|
|
|
|

 AlpinDale
AlpinDale
{kind=link}